
はじめに
ライフログ・プロジェクトとして、家庭内の会話を自動で録音・文字起こし・要約するシステム 「VoiceLog」 を開発しました。主な用途として、家族間の「言った・言ってない問題」の解決、買い物や予定のメモ、将来の出来事検索などを想定しています。
クラウドのAPIに頼りきりになるとコストやプライバシーの懸念がありますが、今回は エッジデバイス(Raspberry Pi) と ローカルの強力なGPU(RTX 4070 SUPER) を連携させることで、高速かつセキュアなハイブリッド環境を構築しました。
本記事では、機材の価格感から実装過程、最新のローカルLLM「Qwen3:8b」を使った要約の仕組みまでの全容を詳細にまとめます。
1. システム「VoiceLog」の全体アーキテクチャ
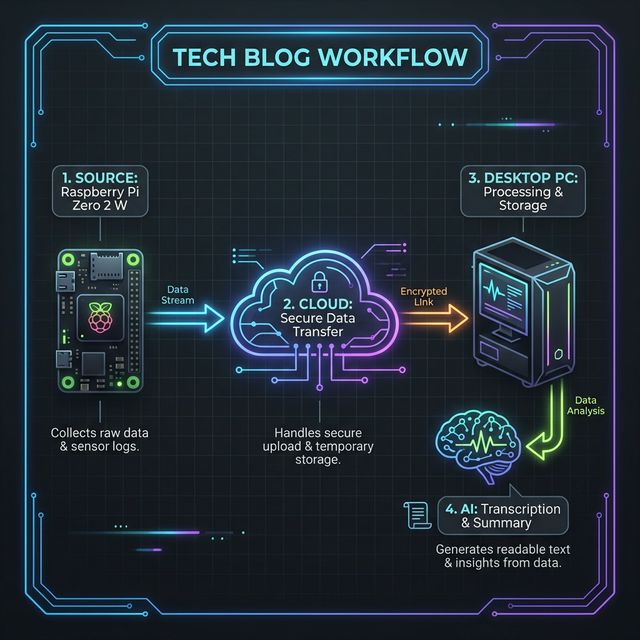
今回のシステムの構成は以下の通りです。
- 【録音・転送】 Raspberry Pi Zero 2 W が音声を検知してWAVで録音。
- 【中継】 録音したデータを rclone を使って Google Drive(
Voice_Log/audio/) へ自動同期。 - 【文字起こし】 メインPCがGoogle Driveを監視し、新しい音声が届いたら Faster-Whisper で即座にテキスト化。幻聴フィルタ処理後、個別の文字起こしとして
transcripts/へ保存。 - 【要約】 1時間ごとに Ollama (qwen3:8b) がテキストを読み込み、要約して
summaries/フォルダへ自動保存。元の音声は削除。
2. 使用した機材・環境スペックと価格
エッジデバイス側は、総額約7,500円という低コストで揃えることができました。(※メインPCの価格は除外しています)
エッジデバイス(録音側)

| 項目 | 詳細 | 価格 |
|---|---|---|
| 本体 | Raspberry Pi Zero 2 W | 約3,500円 |
| マイク | サンワサプライ製 USBマイク | 約3,000円 |
| ストレージ | MicroSDカード 32GB | 約1,000円 |
| OS | Raspberry Pi OS (Debian) | — |
省電力・省スペースで常時稼働に最適な構成です。
メインPC(解析側)
| 項目 | 詳細 |
|---|---|
| CPU | AMD Ryzen 7 5700X |
| GPU | NVIDIA GeForce RTX 4070 SUPER 12GB |
| メモリ | 32GB |
| OS | Windows 11 |
| AIモデル | Whisper (large-v3) / Ollama (qwen3:8b) |
3. 実装フェーズ1:Raspberry Piのセットアップとマイク設定
3-1. OSのインストールと初期設定
Raspberry Pi Imagerを使用し、Raspberry Pi OSをmicroSDカードに書き込みました。この際、ディスプレイやキーボードを繋がずに済むよう、Imagerの設定画面でWi-FiのSSIDとSSHを有効化する 「ヘッドレス・セットアップ」 を行いました。
起動後、メインPCのターミナルからSSH接続(ssh ユーザー名@ホスト名.local)を行い、作業を進めます。
3-2. マイクの認識とALSA設定
USBマイクを接続し、arecord -l コマンドで認識されているカード番号を確認します。デフォルトの録音デバイスとして認識させるため、~/.asoundrc を作成し以下の設定を記述しました。
pcm.!default {
type hw
card 1
}これで、録音コマンド実行時にいちいちデバイスを指定する手間が省けます。
4. 実装フェーズ2:録音の自動化とノイズ対策
次に、音声録音ツールである SoX(コマンドは rec)を使用して、自動録音スクリプト recorder.sh を作成しました。
4-1. 無音カットと周波数フィルター
ただ録音し続けるとファイルサイズが膨大になるため、「声がした時だけ録音する」仕組みを取り入れました。
AUDIODEV=hw:1 rec -q -c 1 -r 16000 "$FILEPATH" \
highpass 300 lowpass 3000 \
silence 1 0.1 0.5% 1 3.0 0.5% 2>/dev/nullhighpass 300 lowpass 3000: 物が落ちた重低音や、食器のぶつかる高音ノイズをカットし、人間の声の帯域だけを拾うフィルター。silence ... 0.5%: 音量が0.5%を超えたら録音開始、3秒間0.5%を下回ったら録音を停止。
4-2. スクリプトの「ゾンビ化」対策
スクリプトを while true でループさせて常時待機状態にしましたが、Ctrl+C を押しても録音コマンド(rec)が止まるだけでループが終了しない 「ゾンビ化」現象 に遭遇しました。
これを解決するため、スクリプトの冒頭に trap "exit" INT TERM を追加し、シグナルを受け取った際にスクリプト全体が綺麗に終了するように改善しました。
5. 実装フェーズ3:Google Driveへの自動転送と常駐化
5-1. rcloneによるクラウド連携
ラズパイに rclone をインストールし、Google Driveへの転送設定を行いました。ラズパイにはブラウザがないため、メインPC側で rclone authorize コマンドを実行してトークンを取得し、それをラズパイ側に貼り付ける手順を踏むことで連携が完了しました。
5-2. systemdによる完全自動化(放置運用)
コンセントを挿すだけで勝手にシステムが起動するよう、systemd にサービスを登録しました。
[Unit]
Description=Frey Recording and Upload Service
After=network-online.target
Wants=network-online.target
[Service]
ExecStart=/bin/bash /home/yuikei/recorder.sh
WorkingDirectory=/home/yuikei
StandardOutput=inherit
StandardError=inherit
Restart=always
User=yuikei
[Install]
WantedBy=multi-user.targetこれを sudo systemctl enable frey-rec.service で有効化することで、24時間稼働の「耳」 が完成しました。
6. 実装フェーズ4:メインPCでのAI処理(Whisper & Qwen3)
ここからが本番、RTX 4070 SUPERのパワーを開放する 「脳」 の構築です。
Windows環境にGoogle Driveアプリを導入し、ファイルが同期される状態を作りました。watchdog ライブラリを使用してGドライブのフォルダを常時監視し、新しいWAVファイルが同期された瞬間に以下の処理が走るPythonスクリプト(brain.py)を実装しました。
- 高速文字起こし:
faster-whisper(large-v3) を使用。GPU処理により、5分の音声が約8秒という爆速でテキスト化されます。プロンプトにローカル情報や家族の固有名詞を事前設定し、認識精度を大幅に向上させました。 - 幻聴フィルタの導入: Whisper特有の「ご視聴ありがとうございました」「チャンネル登録」といった幻聴や、15文字未満の不要なノイズテキストを自動で除外する独自フィルタを組み込みました。
- 1時間ごとのローカルLLM要約: 日本語に極めて強い最新モデル Ollama (qwen3:8b) を採用。1時間分のテキストを結合して渡し、内容を要約させる処理を実装しました。
これにより、最終的に summaries フォルダに「〇〇時のまとめ」という整頓されたテキストが自動生成される仕組みが完成しました。
7. 実装フェーズ5:Web UI「VoiceLog Console」の構築
「解析してファイルに保存する」だけでは、過去の記録を振り返るハードルが高くなります。そこで、溜まったログを直感的にブラウジングし、家族で共有できる 専用のWeb UI を実装しました。

以下は実際に稼働しているVoiceLog Consoleのスクリーンショットです。
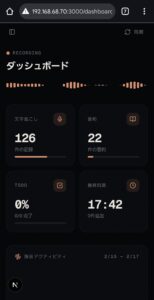
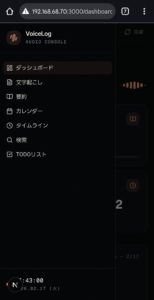
7-1. フロントエンド・スタック
最新の技術スタックを採用し、高速で堅牢なインターフェースを目指しました。
| 項目 | 技術 |
|---|---|
| Framework | Next.js 16 (App Router) / TypeScript |
| Styling | Tailwind CSS 4 + shadcn/ui |
| Database | Prisma 5.x + SQLite(メタデータ管理用) |
Design Concept: 「高級オーディオコンソール」をテーマにしたダークモード。コッパー(銅色)のアクセントとグラスモーフィズム、ノイズテクスチャを施し、ガジェットとしての所有欲を満たすデザインに仕上げました。
7-2. Google DriveとSQLiteの同期エコシステム
データの整合性を保つため、brain.py(解析側)とWeb UI側で役割を分担しています。
- 保存:
brain.pyはこれまで通りGoogle Drive(Gドライブ)へテキストを書き出す。 - 同期: Web UIのダッシュボード読み込み時に
POST /api/syncが走り、Gドライブ上の新規ファイルをスキャン。 - 高速化: メタデータ(ファイル名、タイムスタンプ、要約の断片など)をSQLiteに登録することで、全文検索や統計表示をミリ秒単位で高速化しました。
7-3. ページ構成と主要機能
計7ページの構成により、膨大なログから「必要な瞬間」を即座に特定できます。
| ページ | パス | 主要機能 |
|---|---|---|
| ダッシュボード | /dashboard |
KPI統計、アクティビティ波形、最新の記録一覧 |
| 文字起こし | /transcripts |
全ログのテーブル一覧。詳細ページは前後ナビ付き |
| 要約 | /summaries |
1時間単位の要約カード。含まれる個別録音へジャンプ |
| カレンダー | /calendar |
日付選択によるピンポイント表示 |
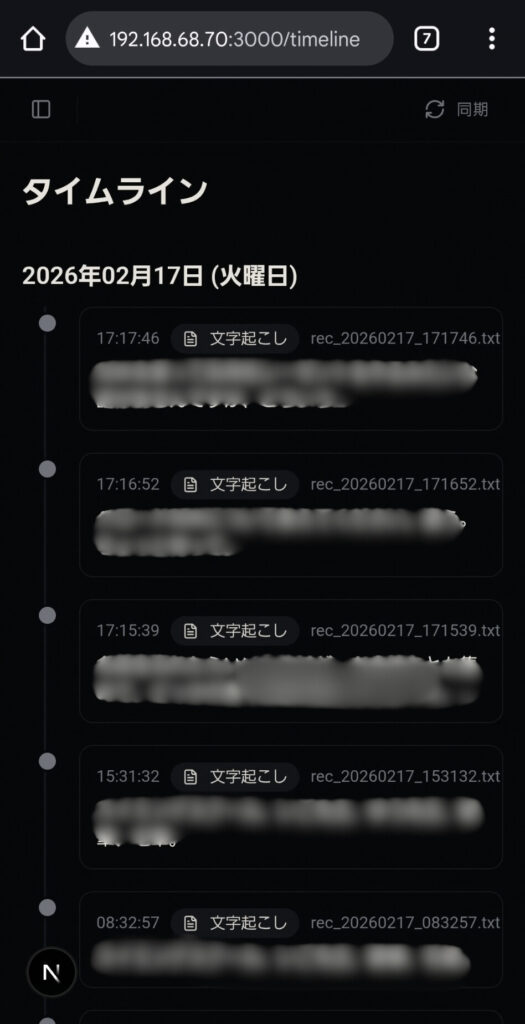
| タイムライン | /timeline |
文字起こしと要約を時系列で統合したストリーム表示 |
| 検索 | /search |
全文検索(300msデバウンスで快適な入力感) |
| TODOリスト | /todos |
会話から抽出されたタスクの管理・完了トグル |
8. 運用で見えてきたメリット
システムが「目に見える形」になったことで、運用の質が劇的に向上しました。
- 「言った言わない」の即時解決:
/searchページからキーワードを入れるだけで、数秒で当時の会話がリプレイ(テキスト確認)できます。 - TODOの漏れ防止: 夕食時の「あれ買っておいて」「明日〇〇時に出発」といった何気ない会話が
/todosに集約されるため、備忘録として機能します。 - プライバシーの担保: 外部サービスにデータをアップロードすることなく、Next.jsをローカルネットワーク内で公開(あるいはTailscale等で保護)することで、究極のプライベート・ライフログを実現しました。
9. まとめと今後の展望
Raspberry Piのコンパクトさと、RTX 4070 SUPERの演算能力、そしてNext.js 16によるモダンなUI。これらが統合されたことで、単なる「録音機」は、家族の記憶を補完する「外部脳」 へと進化しました。
今後は、ChromaDB を用いたベクトル検索の実装により、「去年のお盆休み、何の話してたっけ?」といった曖昧な質問にAIが答える セマンティック検索機能 を追加し、さらに「家族の記憶」へのアクセス密度を高めていく予定です。